// ~/project
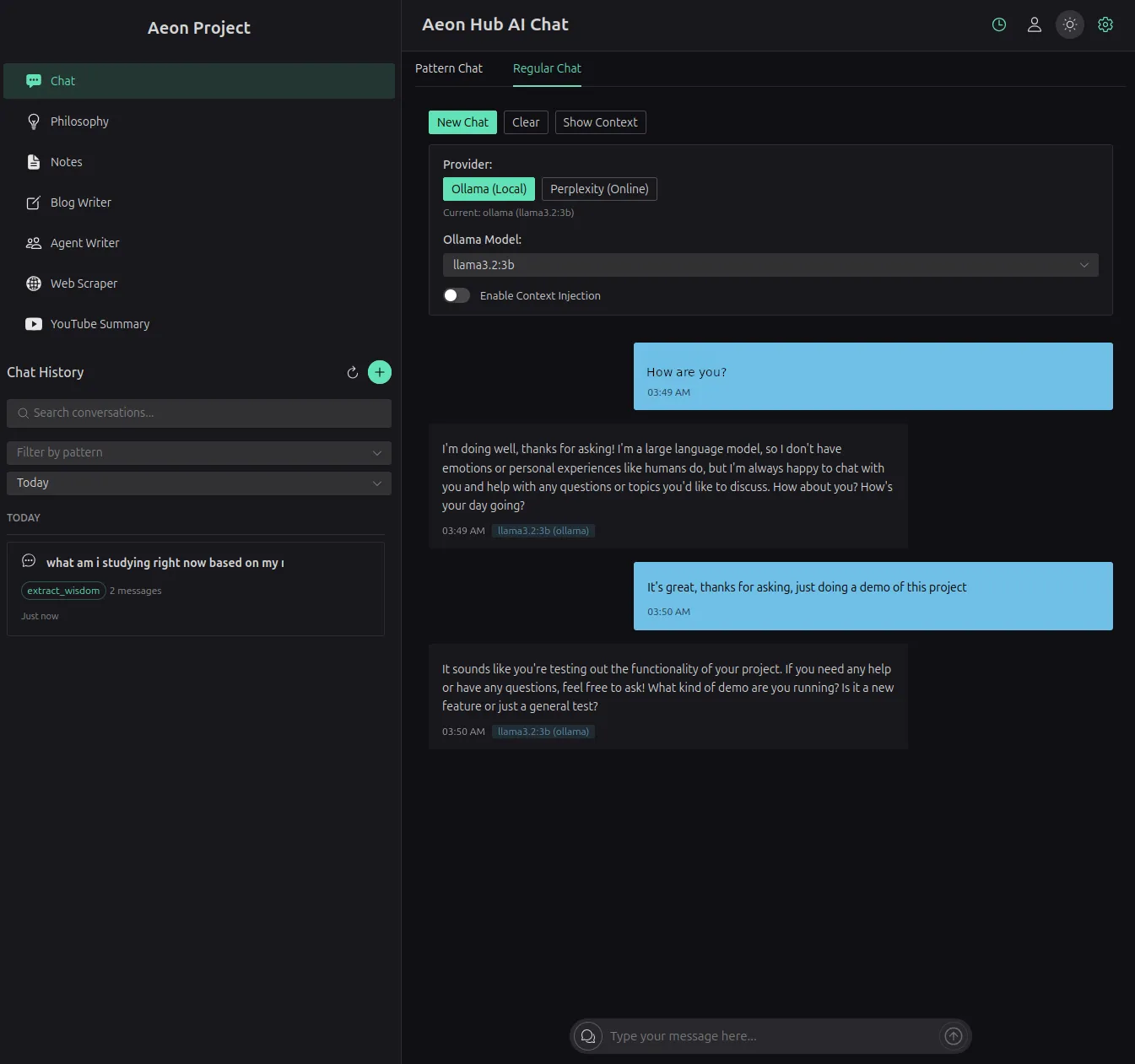
Project Aeon: Local-First Assistant Platform
Built a private local AI assistant without sending work to cloud. Stack: FastAPI, ChromaDB, Ollama, Vue.
// ~/project
Built a private local AI assistant without sending work to cloud. Stack: FastAPI, ChromaDB, Ollama, Vue.